本文译自「GPU-Accelerated Effects: Glitch at Scale」,原文链接https://medium.com/@konstantinzolotov/gpu-accelerated-effects-glitch-at-scale-e59216afd1e8,由Konstantin Zolotov发布于2025年11月9日。

几周前,我看到了Sina Samaki撰写的一篇关于使用Jetpack Compose制作故障效果的精彩文章。作为一个喜欢钻研底层技术的人,我看到了使用Android AGSL着色器重现这种效果并比较两种实现方式的绝佳机会。
在图形处理方面,选择合适的工具至关重要,因为很容易达到性能瓶颈,而扩展解决方案则变得困难。这里的情况是否如此呢?让我们一探究竟!
做好准备,我们将深入底层。
着色器(Shader)的本质
那么,着色器究竟是什么?
着色器是一种直接在 GPU 上执行的程序,并且可以并行执行。
着色器通常使用一种特殊的类 C 语言编写,在 Android Compose 中,这种语言是 AGSL——Android 图形着色语言。
我不会重复官方指南的内容,而是会简单介绍一下 GPU 以及一种新的着色器编程思维模型。
那么,它与 CPU 有什么区别呢? CPU 和 GPU 的主要区别基本上如下:
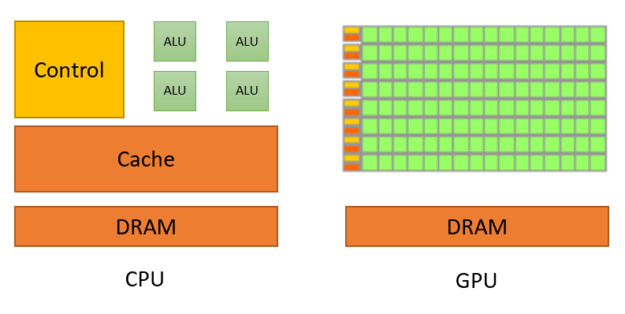
CPU:
- 更复杂
- 专为执行大量不同任务的大型程序而设计
- MIMD(多指令多数据流)
GPU:
- 简单得多(没有分支预测,缓存更小)
- 专为对各种数据执行完全相同操作的小型程序而设计
- 更多核心 = 更高的并行性
- SIMD(单指令多数据流)
当然,CPU 也有 SIMD 扩展,但规模远不及 GPU。
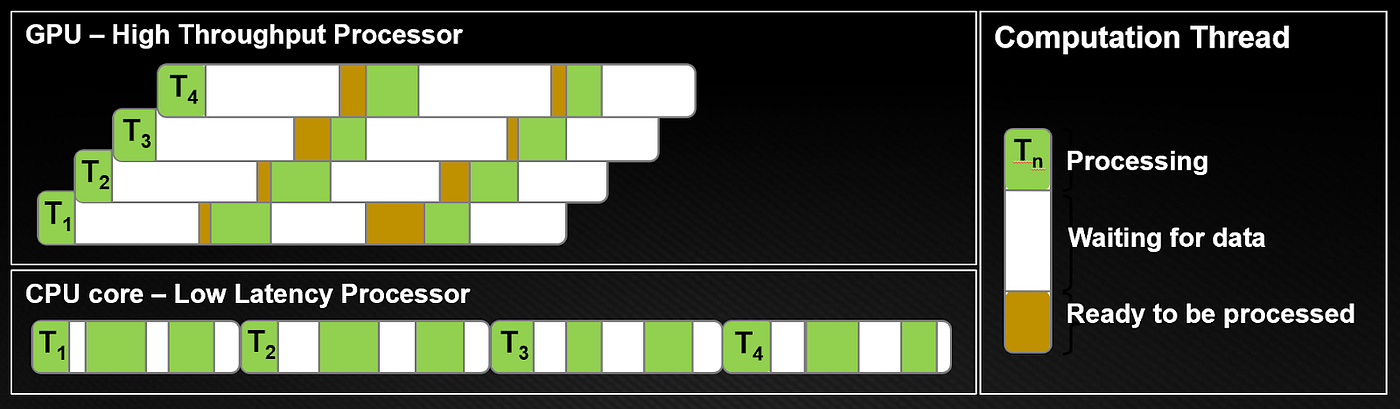
GPU 非常适合对数百万像素执行相同的操作
这里存在一个非常重要的思维模型转变:以前你可以在画布的任意位置绘制,而现在你面对的是一幅图像,你可以对图像的任何部分进行采样(读取),但输出结果始终是一个像素。每个目标像素都会执行相同的着色器。这类似于一个纯函数,不会产生任何副作用,因此像素仅取决于其坐标和提供的 uniform 变量。
让我们开始实现吧,但首先,分析原始合成版本中的关键点,并将这些想法转化为着色器思维模型。
关键的动画驱动因素是步长。动画器会在 500 毫秒的周期内,将浮点数值从 10 递减到 0。步长状态为整数,由于浮点数会被转换为整数,因此共有 11 个步长。
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
此外,还有一个名为强度的参数,它基于步长计算:
1
| |
因此,强度是一个数值序列 [1.0, 0.9, …, 0.0]。
下一个关键点是切片:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
对于每个切片,都会应用以下变换:
1. 平移
- 在步骤 10 到 5 期间,每个切片会随机移动 -20 到 20 范围内的像素。请注意,每一步操作都会使该范围缩小,因为它会乘以强度。
- 在步骤 4 到 0 中也会发生类似的情况,但并非每个切片都会移动,有些切片不会被移动。
2. 水平缩放 每个切片都会根据强度乘以 1.0 到 2.0 范围内的随机数进行缩放,每一步操作都会降低缩放的概率和大小。
3.彩色条纹
- 在步骤 10 到 5 中,在每个切片上绘制一条随机彩色条纹,初始概率为 0.2,到步骤 5 时降至 0。
- 步骤 5 之后不再绘制条纹。
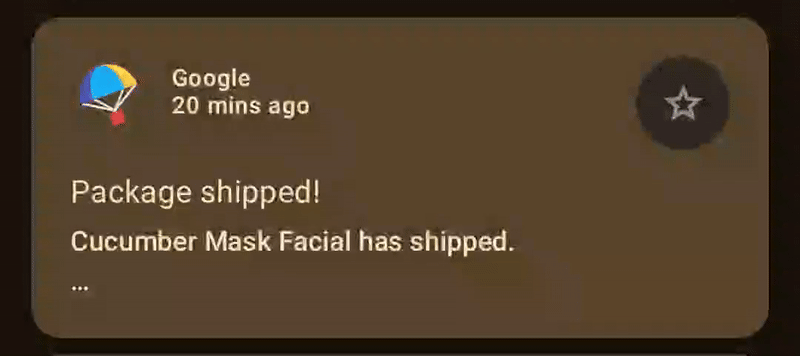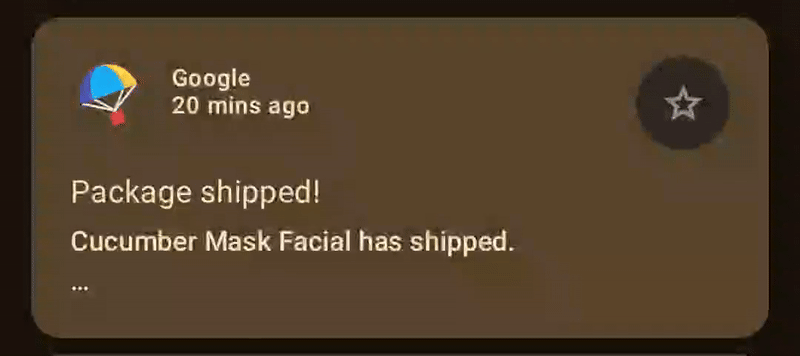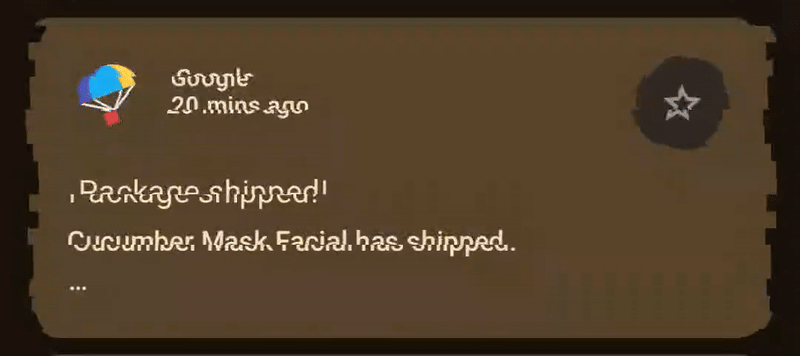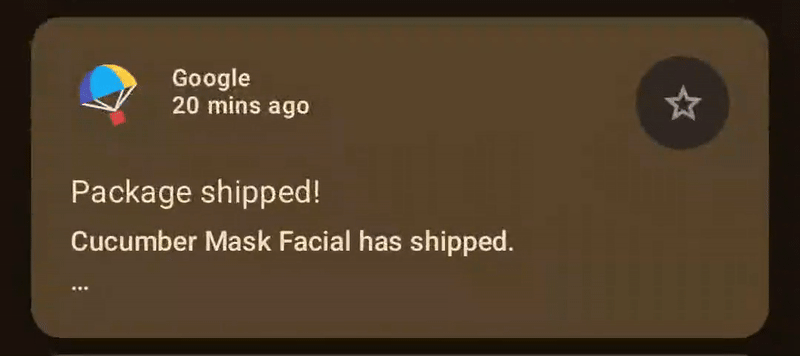
因此,总体而言,动画在前几个步骤中最具表现力,并在后半部分逐渐趋于稳定。
对于着色器而言,强度应该足以驱动动画,而无需使用步骤。在 Kotlin 代码中,我仍然会使用步骤 + 强度,仅仅是为了尽可能地复现动画效果,并用于未来的性能测试。
思维模型转变: 着色器是逐像素执行的,但动画会将相同的变换应用于像素组(在本例中为切片)。为了在着色器中实现这一点,我们需要对整个切片进行完全相同的计算。还记得纯函数的相似性吗?它在这里非常有用,因为要得到相同的结果,我们只需要应用相同的参数!
具有相同变换的像素组就是一个切片:
1 2 3 4 5 6 7 8 9 10 11 | |
让我们一步一步来,从平移开始。
平移
步骤 10 到 5 等价于强度从 1.0 到 0.5,每次递减 0.1。因此,我们将以此为基础来移动切片:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
这里发生了什么?
首先,是随机性。由于着色器本身没有随机性,因此通常使用一些函数来模拟随机性。这两个函数都会返回一个介于 0(含)和 1(不含)之间的浮点值。在这种情况下,“随机”值对于每个切片-帧组合都是唯一的。对于给定帧,均匀强度对于所有调用(= 输出像素)都是相同的,同一组像素的切片坐标也相同。结合切片起始坐标,这个值对于每一帧的每个切片都是不同的。
接下来,如果强度超过 0.5,shouldDisplace 因子会立即设置为 1.0,这意味着切片需要进行位移。否则,intensity > rnd * 0.4 会导致执行位移的概率下降,类似于原始实现中的 Random.nextInt(5) < step。
最后一行只是简单的算术运算。这里我将 0 到 1 的伪随机值转换为 -20 到 20,然后像原始实现一样乘以强度,并在发生位移时应用该因子。
缩放
屏幕空间缩放本质上是指相对于枢轴点(本例中为水平中心)调整像素采样坐标。由于我们是从源图像读取数据,因此实际上是移动了采样视口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
附注:为了演示,我尽量简化了逻辑。生产环境中的着色器代码通常会使用更高级的技术来避免分支,因为像上面示例中那样的不平衡分支会迫使 GPU 串行执行两条路径,从而破坏并行性。要以优化的方式实现缩放函数并非易事,所以我采用了一种简单的方法。
再次强调,对于每一帧的每个切片,随机数都是唯一的,这意味着特定切片中的每个像素都会获得相同的值。因此,rnd < intensity 会降低概率,类似于 Random.nextInt(10) < step。
彩色条纹
最简单的部分。类似地,如果应用了色带,则创建相同的概率,然后选择 3 种颜色中的一种。可以使用非硬编码值,但这需要一些额外的工作,因此 Compose 版本在这方面更灵活。
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
将所有内容组合在一起后,结果如下:
存在一个明显的问题:叠加层的颜色始终为青色。这是因为伪随机函数对相同的输入返回相同的值——这是设计上的确定性行为。解决方案:在 Kotlin 端生成真正的随机数,并将其作为 uniform 变量传递。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
应用适当的随机性后,整个过程与原始行为非常接近:

完整代码发布于此处。
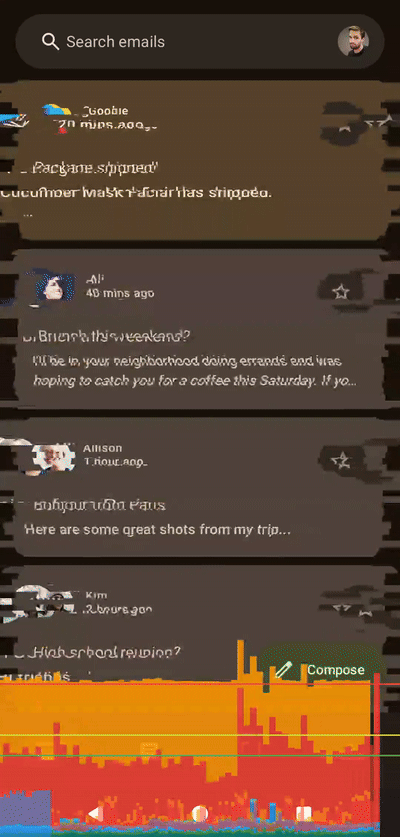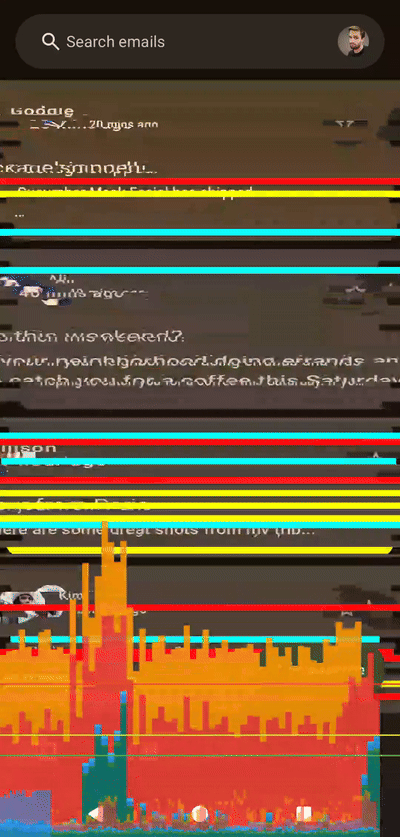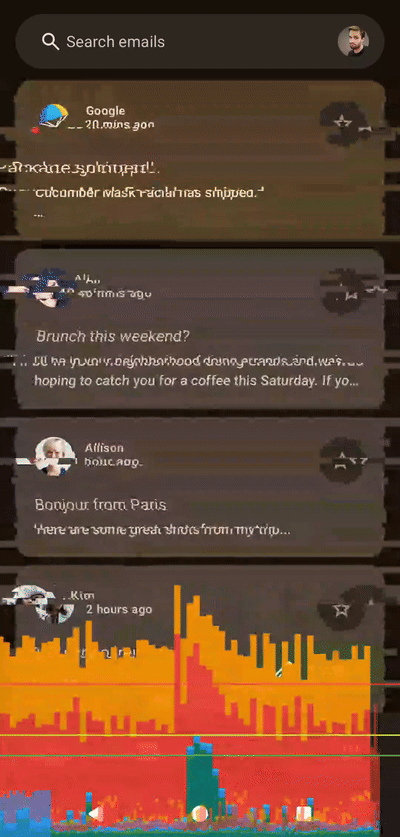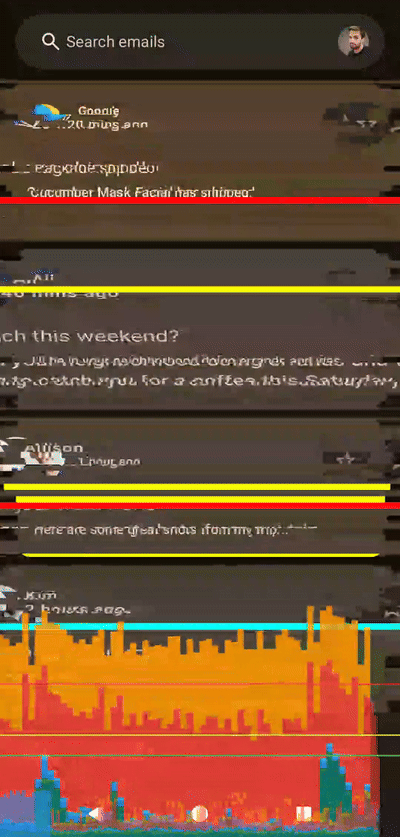
当然,在进行图形编程时,至少需要进行一些粗略的性能观察。为此,我将使用我的 Pixel 7,启用 HWUI 渲染图表,并稍作修改代码:使用 infiniteRepeatable 规范实现循环动画,并使用发布版本。Pixel 7 实际上非常适合这项任务,因为它并非高端设备,如果它在 Pixel 7 上有效,那么在性能更高的设备上也应该有效。

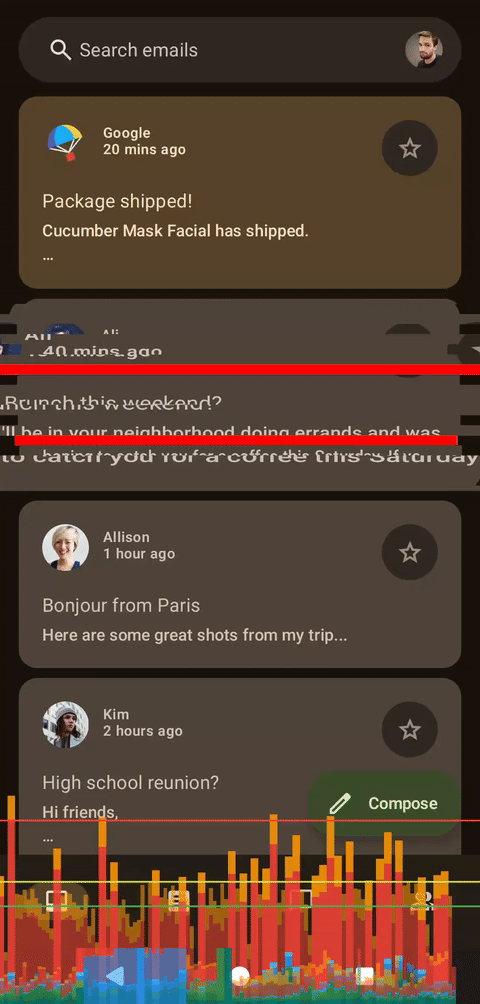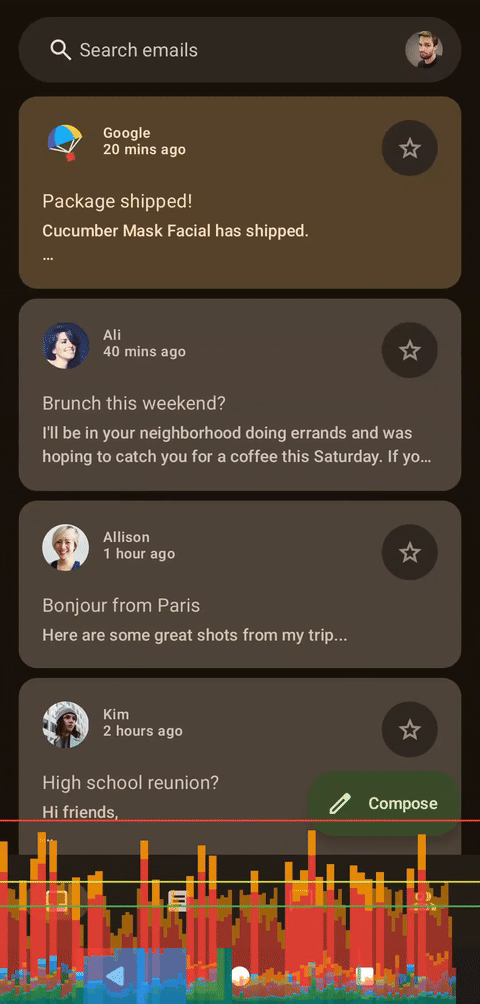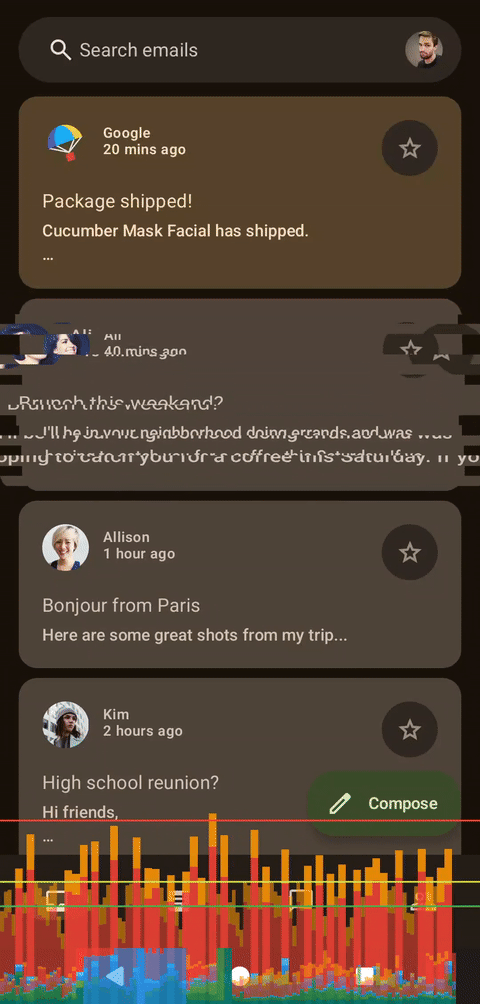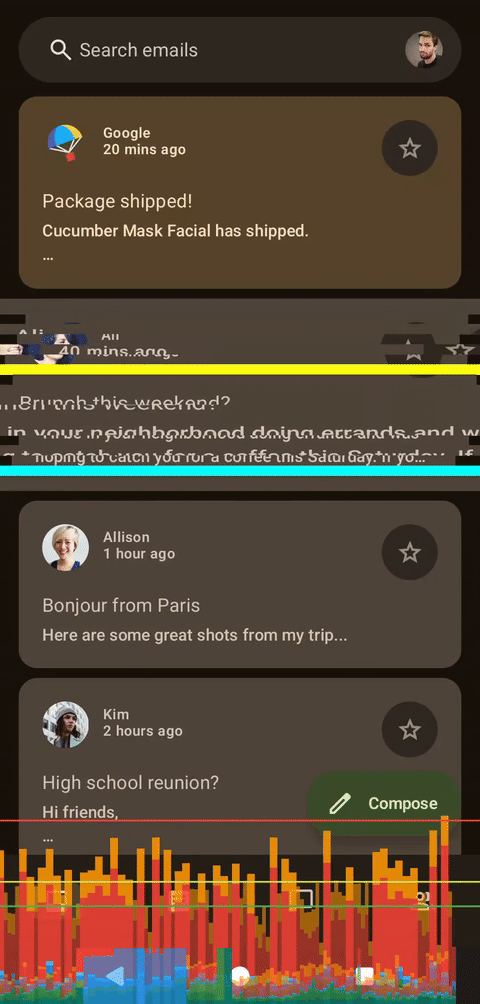
左侧为着色器,右侧为Compose
乍一看,这两个图表似乎很相似,但实际上存在一个问题:当前的实现方式隐式地限制了帧速率。动画会将浮点数值从 10 递减到 0,但状态更新时会使用四舍五入为整数的值。这意味着在 500 毫秒内只有 11 帧动画。这对于故障着色器来说非常方便,因为较低的帧速率也会增强故障效果。要消除这个限制,我们只需要将步长类型从整数 (Int) 更改为浮点数 (Float),并使用不进行四舍五入的可动画值即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
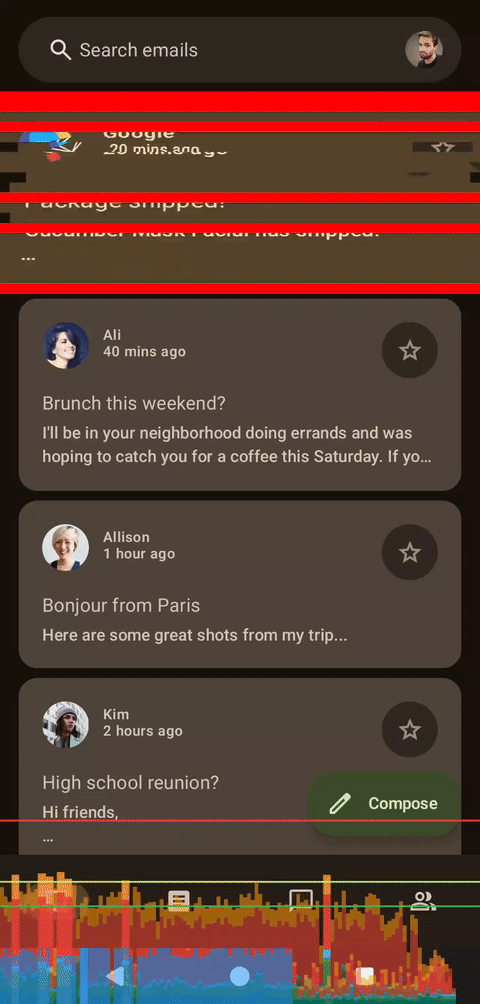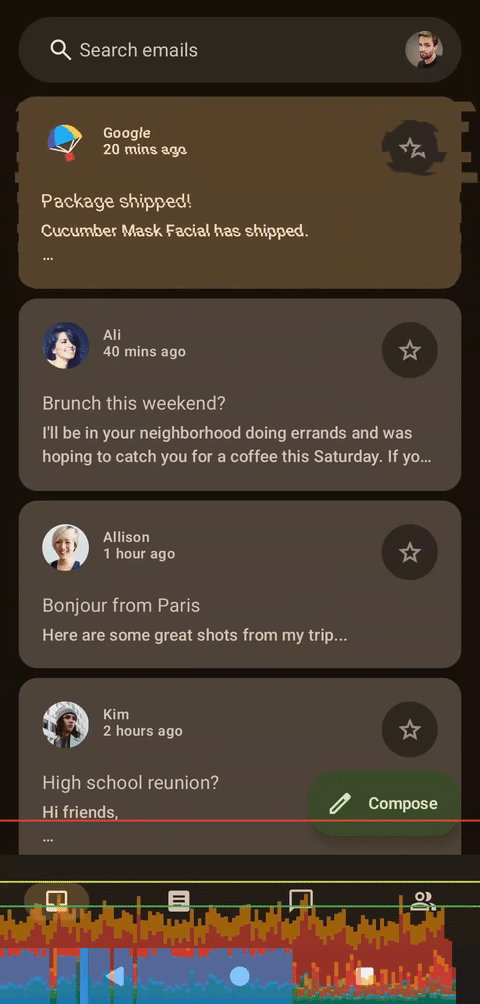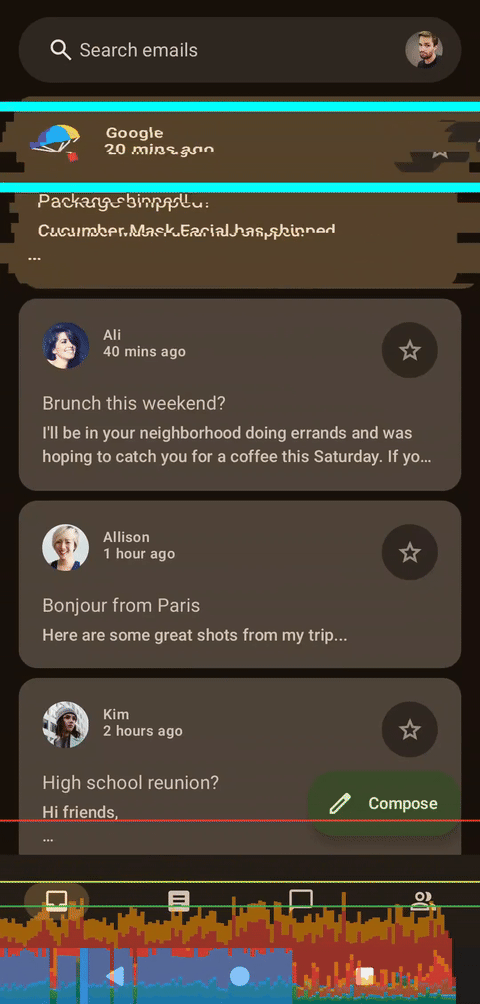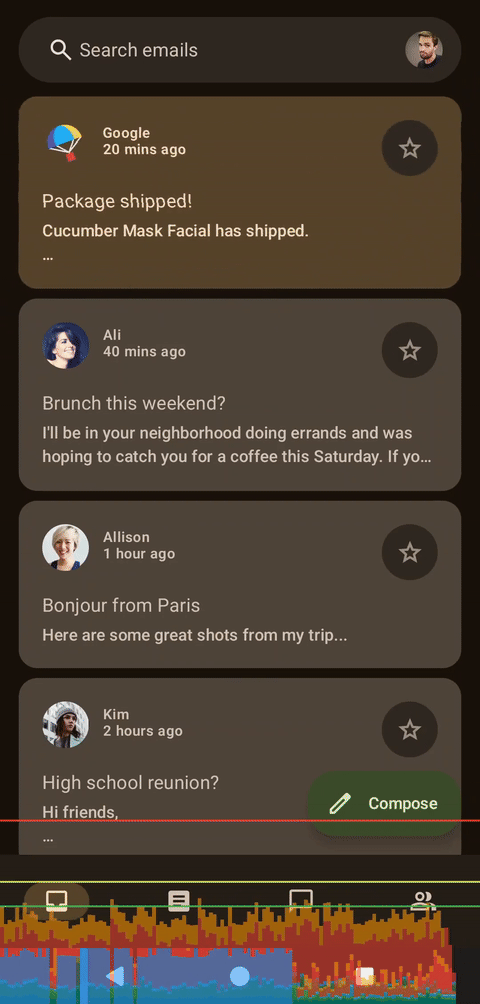
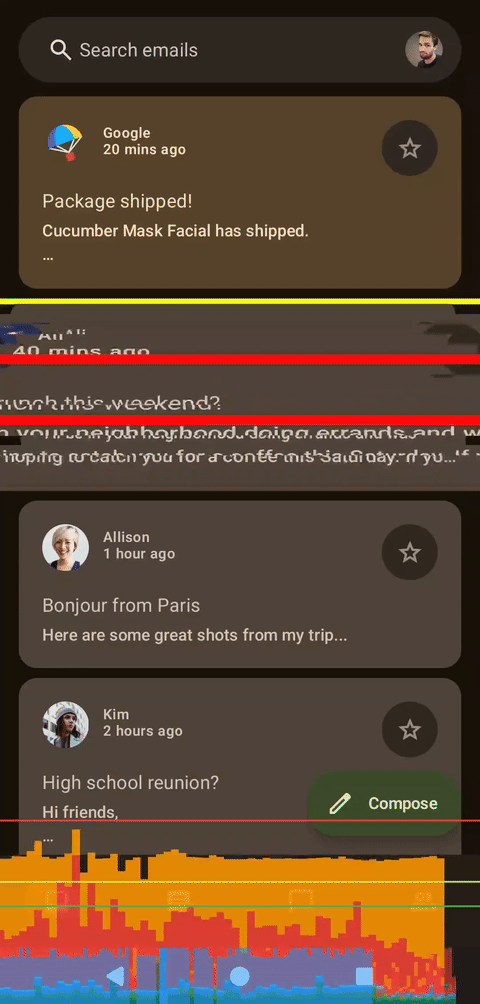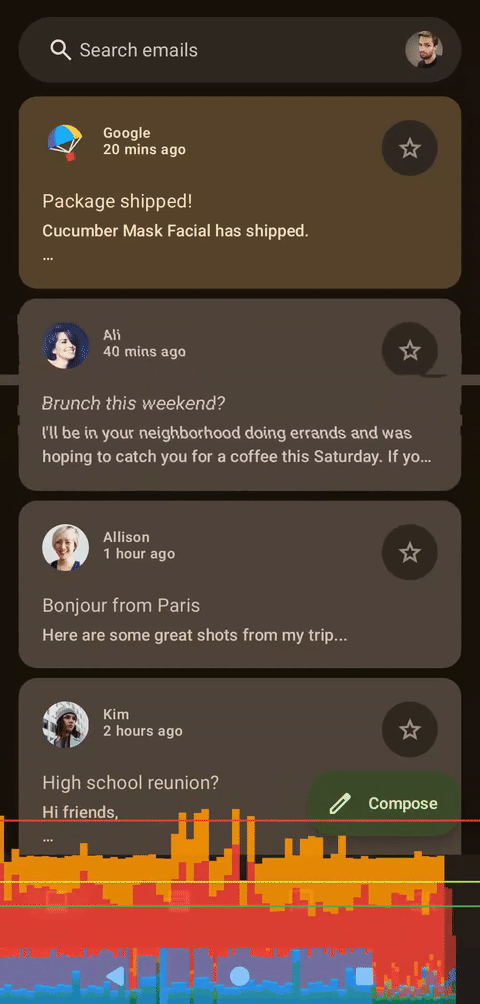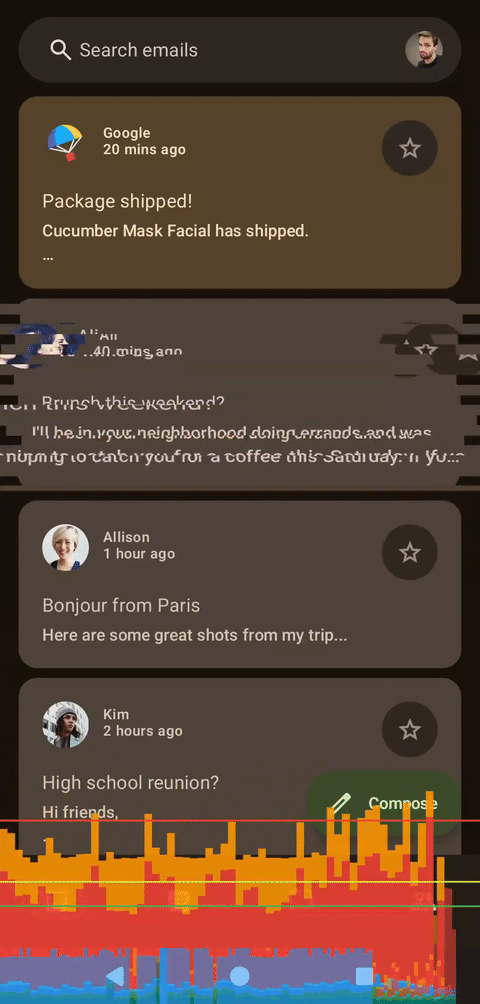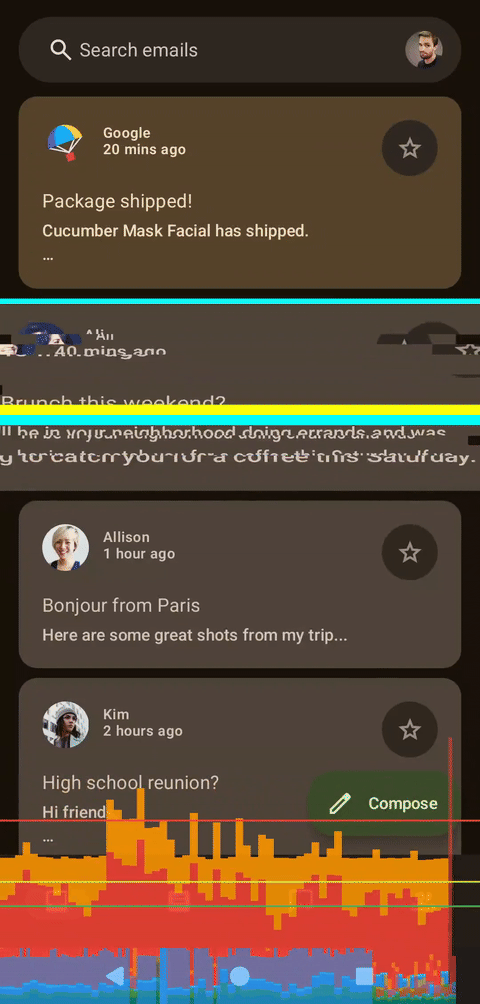
左侧为着色器,右侧为Compose,无帧数限制
移除帧数限制后,性能提升已经非常明显。我们来做个压力测试。如果将动画应用于整个列表会发生什么?或者切片数量增加会发生什么?让我们拭目以待!
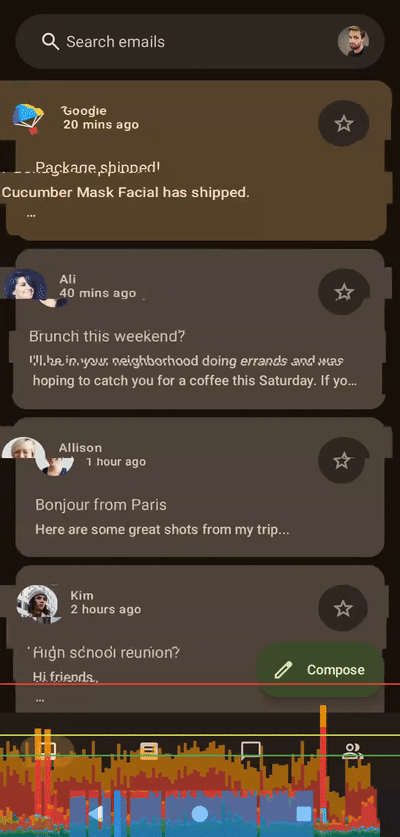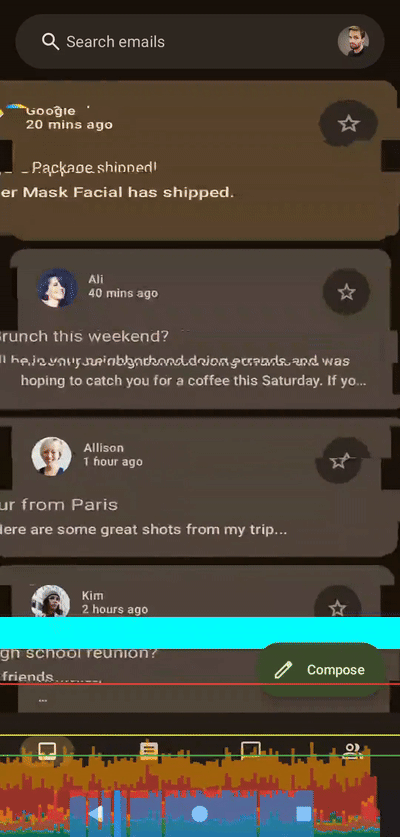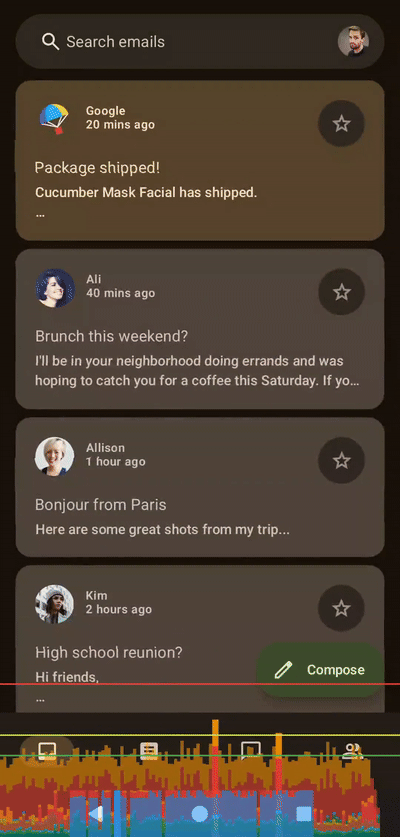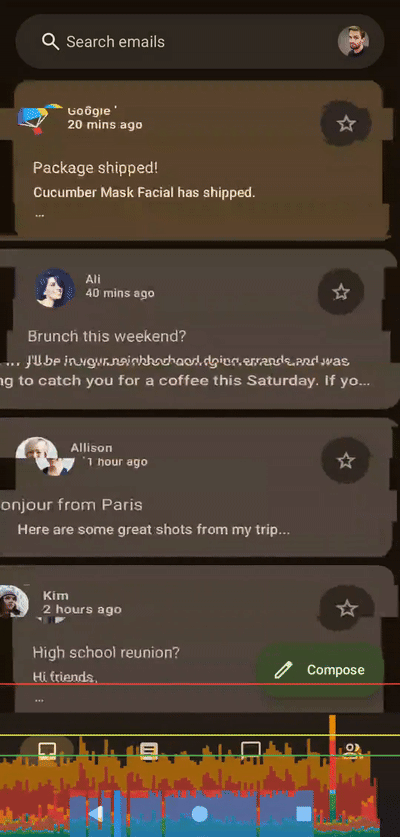
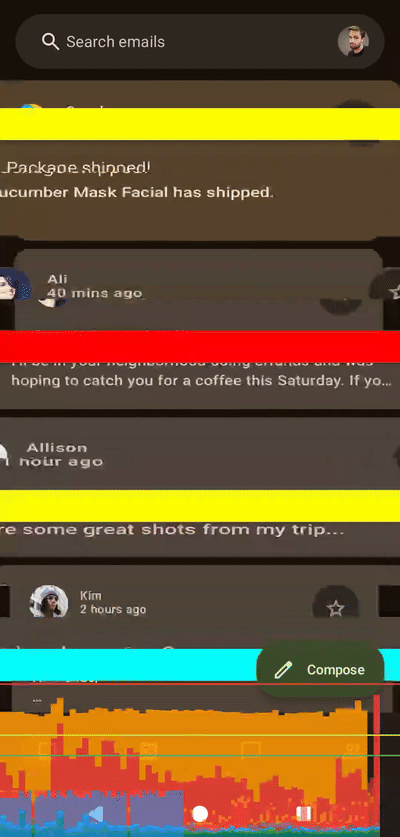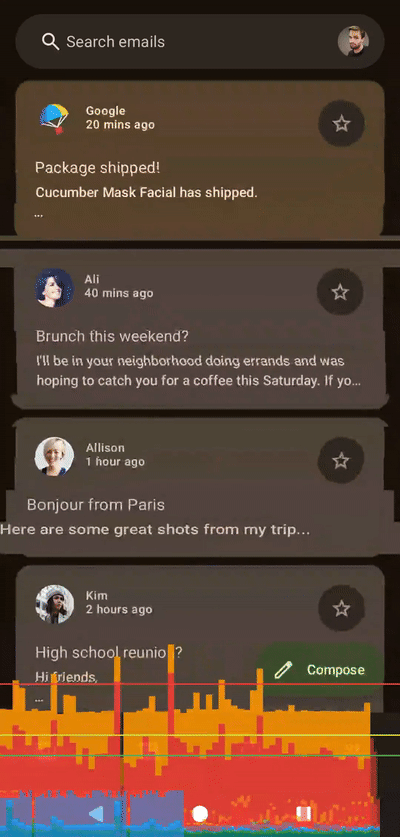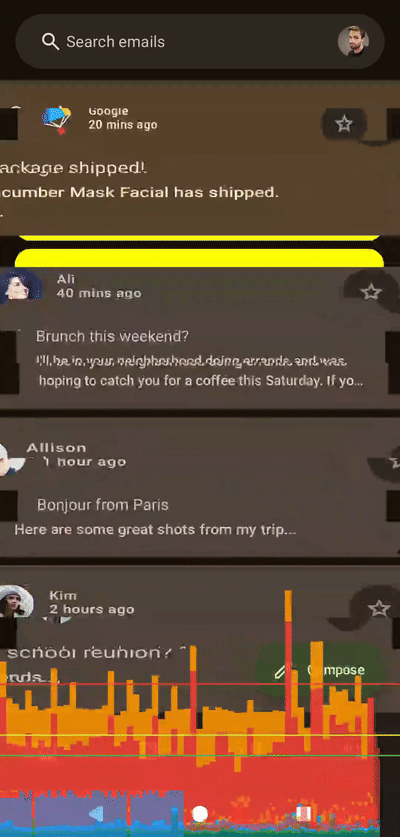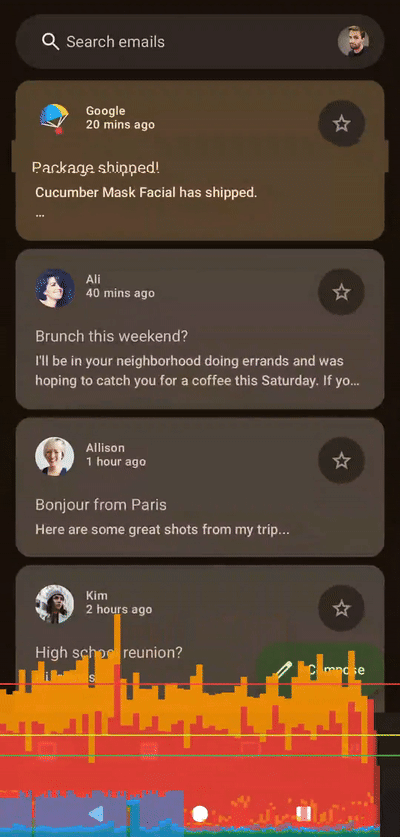
左侧着色器,右侧Compose,无帧数限制,应用于整个列表

左侧着色器,右侧Compose,无帧数限制,应用于整个列表100 个切片
结论
Compose 非常适合用于复杂动画的原型设计,因为它可以使用熟悉的工具轻松实现。此外,值得一提的是,它适用于所有设备。
另一方面,着色器提供了性能更高、更稳定的渲染。在这种情况下,使用的切片数量无关紧要——无论是 20 个还是 500 个,计算量都没有区别,而纯 Compose 版本对此非常敏感,并且会随着切片数量的增加而线性增长。
此外,由于 AGSL 着色器只是在运行时临时编译的文本,因此理论上可以从后端更新这些动画。
但是,还有一个很大的问题:着色器从 Android 13 开始可用,因此根据 Android Studio 操作系统的发行情况,大约一半的设备将能够支持这种方法。当然,这种情况会随着时间的推移而改变,我希望我们能够利用着色器充分发挥图形编程的强大功能!
这是我的bento,如果你想联系我、聊天或讨论,欢迎来找我!